Chapter 2 Frog Families & HMMs
Previously, we wanted to study the weather. Let’s up the stakes and now look at how the weather can determine whether or not a cute, infinitely reproducing, frog-family survives the month.
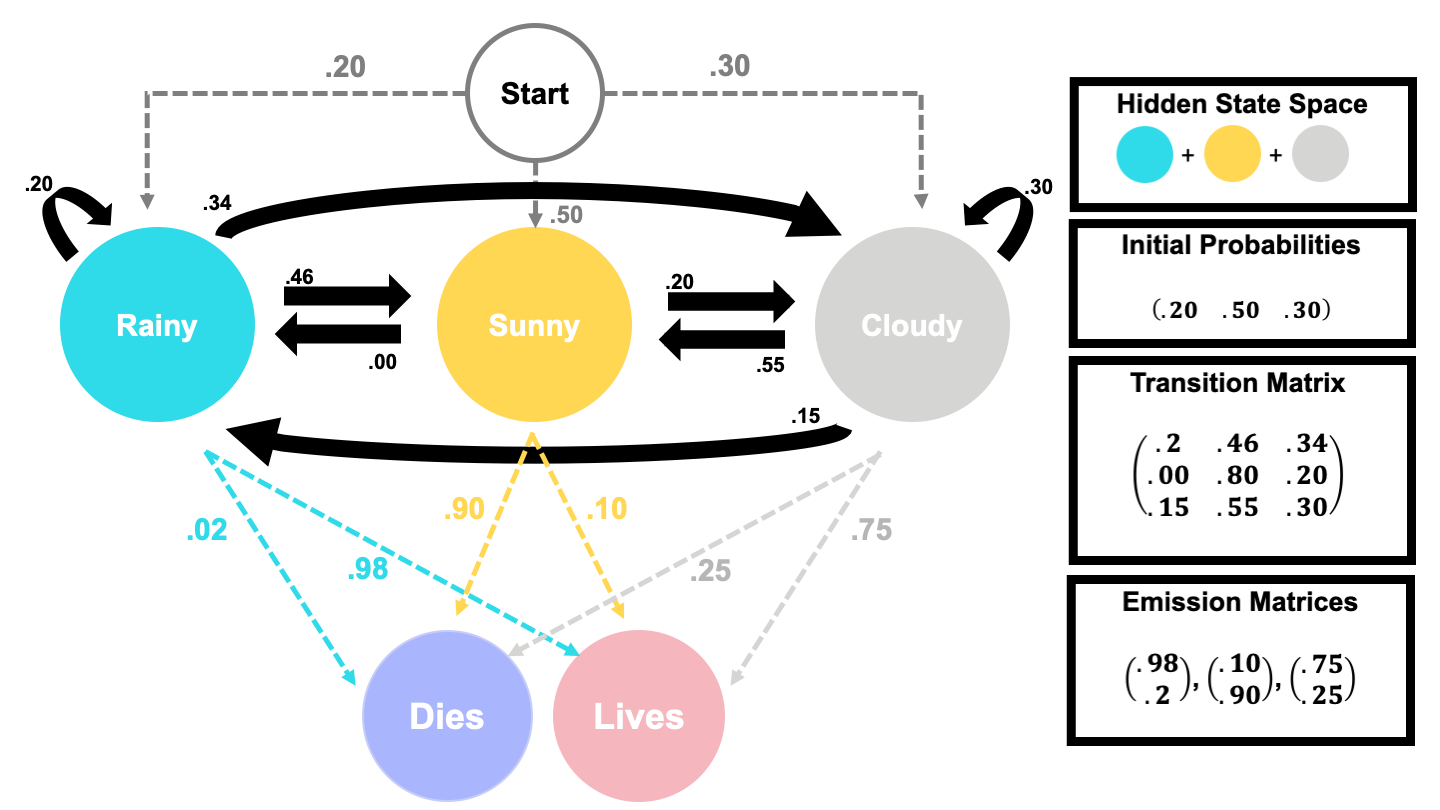
If you were a frog, you wouldn’t be able to check the weather before leaving your tree hide– you wouldn’t even be able to read!– but you do know that when a family member leaves for their daily hop, their chance of living depends on the weather. If the weather is
- Sunny: they would have a 10% chance of living (and eating a nice bug) with a 90% chance of dying.
- Cloudy: they would have a 75% chance of living (and eating a nice bug) with a 25% chance of dying.
- Rainy: they would have a 98% chance of living (and eating a nice bug) with a 2% chance of dying.
Since we, as non-frog statisticians, know that the weather is a Markov Chain, we can say the survival of this frog-family is actually a Hidden Markov Model. In the following sections, we will establish what that implies theoretically for us & our frog family.

2.2 Algorithms
Let’s say the frog family has been really lucky, and all the frogs who left the tree hide in the past week came back! One very curious frog named Betsy wonders what the probability of all her family surviving is, given the weather.
We can answer Betsy’s questions using likelihood calculations or the Forward-Backward Algorithm.
Likelihood
Likelihood or Posterior Probability are commonly defined as the probability of the data, given a true underlying parameter5.
Let \(W_i\) be the hidden states of the weather in the past week, and let \(D_i\) be our observations on whether or not the frogs came back alive. This implies
\[\begin{align*} W_i &= \{W_1= w_1, W_2=w_2, W_3=w_3,W_4= w_4, W_5=w_5, W_6=w_6, W_7=w_7\}\\ W_i &= \{w_1, w_2, w_3, w_4, w_5, w_6, w_7\} \\[15pt] \text{and}\\[15pt] D_i &= \{D_1= d_1, D_2=d_2, D_3=d_3,D_4= d_4, D_5=d_5, D_6=d_6, D_7=d_7\\ D_i &= \{d_1, d_2, d_3, d_4, d_5, d_6, d_7\} \end{align*}\]
In this case, the likelihood would be the probability of our observed \(D_i\), given some true underlying set of \(W_i\). This is computed below.
\[\begin{align*} P(D_i \mid W_i) &= P(d_1 \mid w_1) \times P(d_2 \mid w_2) \\ & \times P(d_3 \mid w_3) \times P(d_4 \mid w_4) \\ & \times P(d_5 \mid w_5) \times P(d_6 \mid w_6) \\ & \times P(d_7 \mid w_7) \\ P(D_i \mid W_i) &= \prod_{i=1}^7 P(d_i \mid w_i) \end{align*}\]
NOTE: The capital pi (\(\prod\)) means to multiply a series indexed by \(i\).
If we knew the states of the past week were Sunny, Cloudy, Rainy, Rainy, Rainy, Rainy, Rainy and everyone came back alive. We’d compute the likelihood as
\[\begin{align*} P(D_i \mid W_i) &= P(Lives \mid Sunny) \times P(Lives \mid Cloudy)\\ &\times P(Lives \mid Rainy)\times P(Lives \mid Rainy) \\ & \times P(Lives \mid Rainy) \times P(Lives \mid Rainy) \\ & \times P(Lives \mid Rainy) \\[10pt] P(D_i \mid W_i) &= .10 \times .75 \times .98 \times .98 \times .98 \times .98 \times .98 \\ P(D_i \mid W_i) &= 0.06779406 \\ P(D_i \mid W_i) &\approx 0.068 \\ \end{align*}\]
Bad News: We can’t truly know the states of the \(W_i\)! Bummer.
Because of this, we would need to add together all likelihoods for all possible states for each event, weighted by their probability6 . More succinctly, we intend to find the likelihood of all observations \(P(D_i)\), given the probability of all states \(P(D_i \cap W_i)\). We can do this with the rules of joint probability we covered in the previous section.
\[\begin{align*} P(D_i \cap W_i) &= P(D_i \mid W_i)\times P(W_i) \\ &= \prod_{i=1}^7 P(d_i \mid w_i) \times P(W_i) && \text{by above}\\ &= \prod_{i=1}^7 P(d_i \mid w_i) \times \prod_{i=1}^7 P(w_i \mid w_{i-1}) && \text{by Markov} \end{align*}\]
Now, we sum up all the observations given.
\[P(D_i) = \sum_{i=1}^n P(D_i \cap W_i) = \sum_{i=1}^n P(D_i \mid W_i)\times P(W_i)\]
So, for our 7 consecutive live frogs, this would be
\[\begin{align*} P(D_i) &=P(Lives \mid Sunny) \times P(Lives \mid Sunny)\times P(Lives \mid Sunny)\\ &\times P(Lives \mid Sunny)\times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \\[10pt] & + P(Lives \mid Cloudy) \times P(Lives \mid Sunny)\times P(Lives \mid Sunny)\\ &\times P(Lives \mid Sunny)\times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \\[10pt] & + P(Lives \mid Sunny) \times P(Lives \mid Cloudy)\times P(Lives \mid Sunny)\\ &\times P(Lives \mid Sunny)\times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \\[10pt] & + P(Lives \mid Sunny) \times P(Lives \mid Sunny)\times P(Lives \mid Cloudy)\\ &\times P(Lives \mid Sunny)\times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \times P(Lives \mid Sunny) \\[10pt] &+ \dots \\[10pt] &=P(Lives \mid Rainy) \times P(Lives \mid Rainy)\times P(Lives \mid Rainy)\\ &\times P(Lives \mid Rainy)\times P(Lives \mid Rainy) \times P(Lives \mid Rainy) \times P(Lives \mid Rainy) \\[10pt] \end{align*}\]
That is extremely difficult to do when we the number of our states (\(N\)) are numerous or we have some arbitrarily large number observations, \(T\), since we’d be analyzing \(N^T\) different possible sequences. However, we can predict the hidden states of HMMs like this one, using the Forward-Backward Algorithm.
The Forward-Backward Algorithm
The Forward-Backward Algorithm is a dynamic programming algorithm used to infer the probability of seeing observations in a Hidden Markov Model. It contains two sub-algorithms, the Forward Algorithm & the Backward Algorithm, which respectively compute the probability of the data from the beginning and the end of observations until they collide and result in a total probability of the data7. The process may seem extra, but as you’ve seen in the last section’s toy computation, we have to be extra out of necessity.
NOTE: The following sections heavily drawn from the following sources 8 9 10 11
Forward
In the first section of the Forward-Backward Algorithm, we compute the forward probabilities. Forward probabilities are informally the joint probability of all observations so far and the probability of being in some given state space.
Formally, a forward probability is defined as \[\alpha_k(j) = P(d_1, \dots , d_k,w_k = j \mid \mathbb{F}) \] > NOTE: That is, we compute the probability of the first \(k\) observations (\(d_1,\dots, d_k\)) leading us to our current observation while also being in state \(j\), \(\alpha_k(j)\).
To compute the forward probabilities, we must
- Sum over all previous forward probabilities that would lead us to be in \(\alpha_k(j)\)
- Multiply by the transition probabilities \(\mathbb{a}_{ij}\) describing the change from the previous state \(i\) to the current state \(j\).
- Multiply again by the emission probabilities of our current observation \(d_k\), given the state \(j\). That is \(b_j(d_{k})\).
Formally, this is written as
\[\alpha_{k}(j) = \left[\sum_{i=1}^\mathbb{W} \alpha_{k-1}(i) \mathbb{a}_{ij} \right]b_j(w_{k})\]
Note: Remember that \(\mathbb{W}\) is the state space!
In practice, we typically use recursion to compute the probability of our observations. Like so
1.) Base Case: We use the initial probability of our system’s states.
\[\begin{align*} \alpha_1(j) = \pi_jb_j(d_1) && \text{for } 1 \leq j \leq \mathbb{W} \end{align*}\]
2.) Recursion: We use the previous case & transition & emission probabilities to compute the probability of being in the newest state \(j\).
\[\begin{align*} \alpha_{k}(j) = \left[\sum_{i=1}^\mathbb{W} \alpha_{k-1}(i) \mathbb{a}_{ij} \right]b_j(d_{k}) && \text{for } 1 \leq j \leq \mathbb{W}, 1 \leq k \leq n \end{align*}\]
2.) End: We can then define the probability of the observations as the recursive sum of all forward probabilities.
\[P(D_{1:n} = d_{1:n} \mid \lambda) = \sum_{i=1}^\mathbb{W} \alpha_{n}(i)\]
Backward
In the second section of the Forward-Backward Algorithm, we compute the backward probabilities. Backward probabilities are informally the joint probability of successive observations and the probability of being in some arbitrary state \(v\), given that we start an observation \(k+1\).
Formally, a backward probability is defined as \[\beta_k(v) = P(d_{k+1}, \dots , d_n, \mid w_k = v , \mathbb{F}) \]
To compute the backward probabilities, we must - Sum the successive values after \(\beta_{k+1}\) until the end of the k-observations at \(d_n\). - Multiply by the transition probabilities \(\mathbb{a}_{vj}\) describing the change from the given current state \(v\) to the next state \(j\). - Multiply again by the emission probabilities of the success observation \(d_{k+1}\). That is \(b_j(d_{k+1})\).
Formally, this is written as
\[\beta_k(v) = \sum_{j=1}^\mathbb{W} \mathbb{a}_{vj}b_j(d_{k+1}) \beta_{k+1}(j) \]
Note: Remember that \(\mathbb{W}\) is the state space!
In practice, we typically use recursion to compute the probability of our observations. Like so
1.) Base Case: We use the initial probability of our system’s states. The value is 1 since we’re working backward!
\[\begin{align*} \beta_n(i) = 1 && \text{for } 1 \leq v \leq \mathbb{W} \end{align*}\]
2.) Recursion: We use the previous transition & emission probabilities of being in the previous state \(i\) from the state \(j\) to weigh the sum of all success values.
\[\begin{align*} \beta_k(v) = \sum_{j=1}^\mathbb{W} \mathbb{a}_{vj}b_j(d_{k+1}) \beta_{k+1}(j) && \text{for } 1 \leq v \leq \mathbb{W}, 1 \leq k \leq n \end{align*}\]
2.) End: We can then define the backward probability of the observations as the recursive sum of values after \(k\), beginning with the end value.
\[P(D_{k+1:n} =d_{k+1:n} \mid \lambda) = \sum^\mathbb{W}_{j=1}\pi_j b_j(d_1)\beta_1(j)\] In the end, we’ve done the same thing! But now, we can use the probabilities of our observations to study the distribution of the hidden states.
Collision
We can use Bayes’ Rule, joint probability, and our previous work to compute the probability of being in a state \(v\) at a given time, \(t\). This is commonly called a smoother analysis. Like before, we will use the notation of our frog example to describe the states (\(W_i\)) and observations (\(D_i\)).
By Bayes’ Rule, the probability of being in state, \(v\), given the observations, is
\[\gamma_t(v) = P(W_t = v \mid D_i) = \frac{P(W_i \cap D_i )}{P(D_i)} \]
However, we can make this simpler by acknowledging that \(P(W_i \mid D_i)\) is proportional (e.g., division by a constant value) to the joint probability of \(W_i\) and \(D_i\). So,
\[\begin{align*} \gamma_t(v) &\propto P(W_i \cap D_i) \\ \end{align*}\]
We can simplify this even further by splitting our \(n\) observations at the \(k^th\) observation, like
- \(D_{i} = \{d_1, \dots, d_n\}\)
- \(D_{1:k} = \{d_1, \dots, d_k\}\)
- \(D_{k+1:n} = \{d_{k+1}, \dots, d_{n}\}\)
Then,
\[\begin{align*} \gamma_t(v) &\propto P(W_i \cap D_i) \\ &\propto P(D_{k+1:n} \mid W_i \cap D_{1:k}) \times P(W_i \cap D_{1:k}) && \text{by Bayes Rule}\\ &\propto P(D_{k+1:n} \mid W_i) \times P(W_i \cap D_{1:k}) && \text{by Markov Property of } D_i\\ \end{align*}\]
We recognize these as the backward probability times the forward. We include our constant value \(\frac{1}{ \sum^\mathbb{W}\beta_t(v) \times \alpha_t(v)}\).
\[\begin{align*} \gamma_t(v) = P(W_t = v \mid D_i) = \text{backward} \times \text{forward} \times \frac{1}{ \sum^\mathbb{W} \beta_t(v) \times \alpha_t(v)} \end{align*}\]
Note: We’ve multiplied by the constant value of \(\frac{1}{ \sum^\mathbb{W}\beta_t(v) \times \alpha_t(v)}\) because the marginal distribution of the \(D_i\) would be the sum of the probabilities of the observations for each possible state, by the Law of Total Probability.
Thus, the probability of being in a given state \(v\), at a particular time, \(t\), given the data is
\[\gamma_t(v) = P(W_t = v \mid D_i) = \frac{\beta_t(v) \times \alpha_t(v)}{\sum^\mathbb{W} \beta_t(v) \times \alpha_t(v)}\]
We did it! Intuitively, it might not make sense why we can compute the probability of being at a state by multiplying the backward & forward probabilities, then dividing by the possible states.
The idea is that the recursive functions “scan” through the observations, determining some probability of the next or previous outcome, until they collide and essentially collapse onto a probability of that observation. They do this for each possible observation. Then, by dividing the total probability of the observations, we can get the probability of the \(v\)-state.
2.3 Conclusion
We did it! We’ve learned how to compute the probability of the observations & the probability of a particular state, given a time, using the Forward-Backward Algorithm. There are, of course, other problems that Hidden Markov Models can solve, like finding the most probable sequence of all states or how to maximize the functions forward or backward functions.
However, the Forward-Backward Algorithm has so many meaningful applications throughout the natural & social sciences alone. We’ll look at a couple in the next chapter.
If you have any lingering questions, I’ve linked some great YouTube videos that may be helpful below.